alpenglow.offline.models package¶
Submodules¶
alpenglow.offline.models.ALSFactorModel module¶
-
class
alpenglow.offline.models.ALSFactorModel.ALSFactorModel(dimension=10, begin_min=-0.01, begin_max=0.01, number_of_iterations=3, regularization_lambda=0.0001, alpha=40, implicit=1)[source]¶ Bases:
alpenglow.offline.OfflineModel.OfflineModelThis class implements the well-known matrix factorization recommendation model [Koren2009] and trains it using ALS and iALS [Hu2008].
Parameters: - dimension (int) – The latent factor dimension of the factormodel.
- begin_min (double) – The factors are initialized randomly, sampling each element uniformly from the interval (begin_min, begin_max).
- begin_max (double) – See begin_min.
- number_of_iterations (double) – Number of times to optimize the user and the item factors for least squares.
- regularization_lambda (double) – The coefficient for the L2 regularization term. See [Hu2008]. This number is multiplied by the number of non-zero elements of the user-item rating matrix before being used, to achieve similar magnitude to the one used in traditional SGD.
- alpha (int) – The weight coefficient for positive samples in the error formula in the case of implicit factorization. See [Hu2008].
- implicit (int) – Whether to treat the data as implicit (and optimize using iALS) or explicit (and optimize using ALS).
alpenglow.offline.models.AsymmetricFactorModel module¶
-
class
alpenglow.offline.models.AsymmetricFactorModel.AsymmetricFactorModel(dimension=10, begin_min=-0.01, begin_max=0.01, learning_rate=0.05, regularization_rate=0.0, negative_rate=0, number_of_iterations=9)[source]¶ Bases:
alpenglow.offline.OfflineModel.OfflineModelImplements the recommendation model introduced in [Paterek2007].
Parameters: - dimension (int) – The latent factor dimension of the factormodel.
- begin_min (double) – The factors are initialized randomly, sampling each element uniformly from the interval (begin_min, begin_max).
- begin_max (double) – See begin_min.
- learning_rate (double) – The learning rate used in the stochastic gradient descent updates.
- regularization_rate (double) – The coefficient for the L2 regularization term.
- negative_rate (int) – The number of negative samples generated after each update. Useful for implicit recommendation.
- number_of_iterations (int) – Number of times to iterate over the training data.
alpenglow.offline.models.FactorModel module¶
-
class
alpenglow.offline.models.FactorModel.FactorModel(dimension=10, begin_min=-0.01, begin_max=0.01, learning_rate=0.05, regularization_rate=0.0, negative_rate=0.0, number_of_iterations=9)[source]¶ Bases:
alpenglow.offline.OfflineModel.OfflineModelThis class implements the well-known matrix factorization recommendation model [Koren2009] and trains it via stochastic gradient descent. The model is able to train on implicit data using negative sample generation, see [X.He2016] and the negative_rate parameter.
Parameters: - dimension (int) – The latent factor dimension of the factormodel.
- begin_min (double) – The factors are initialized randomly, sampling each element uniformly from the interval (begin_min, begin_max).
- begin_max (double) – See begin_min.
- learning_rate (double) – The learning rate used in the stochastic gradient descent updates.
- regularization_rate (double) – The coefficient for the L2 regularization term.
- negative_rate (int) – The number of negative samples generated after each update. Useful for implicit recommendation.
- number_of_iterations (int) – Number of times to iterate over the training data.
alpenglow.offline.models.NearestNeighborModel module¶
-
class
alpenglow.offline.models.NearestNeighborModel.NearestNeighborModel(num_of_neighbors=10)[source]¶ Bases:
alpenglow.offline.OfflineModel.OfflineModelOne of the earliest and most popular collaborative filtering algorithms in practice is the item-based nearest neighbor [Sarwar2001] For these algorithms similarity scores are computed between item pairs based on the co-occurrence of the pairs in the preference of users. Non-stationarity of the data can be accounted for e.g. with the introduction of a time-decay [Ding2005] .
Describing the algorithm more formally, let us denote by
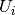 the set of users that visited item
the set of users that visited item 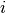 , by
, by 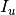 the set of items visited by user
the set of items visited by user 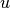 , and by
, and by 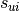 the index of item in the sequence of interactions of user . The frequency based similarity function is defined by
the index of item in the sequence of interactions of user . The frequency based similarity function is defined by 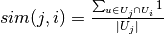 . The score assigned to item for user is
. The score assigned to item for user is 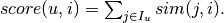 The model is represented by the similarity scores. Only the most similar items are stored for each item. When the prediction scores are computed for a particular user, all items visited by the user are considered.
The model is represented by the similarity scores. Only the most similar items are stored for each item. When the prediction scores are computed for a particular user, all items visited by the user are considered.Parameters: num_of_neighbors (int) – Number of most similar items that will be stored in the model.
alpenglow.offline.models.PopularityModel module¶
-
class
alpenglow.offline.models.PopularityModel.PopularityModel[source]¶ Bases:
alpenglow.offline.OfflineModel.OfflineModelRecommends the most popular item from the set of items.
alpenglow.offline.models.SvdppModel module¶
-
class
alpenglow.offline.models.SvdppModel.SvdppModel(dimension=10, begin_min=-0.01, begin_max=0.01, learning_rate=0.05, negative_rate=0.0, number_of_iterations=20, cumulative_item_updates=false)[source]¶ Bases:
alpenglow.offline.OfflineModel.OfflineModelThis class implements the SVD++ model [Koren2008] The model is able to train on implicit data using negative sample generation, see [X.He2016] and the negative_rate parameter.
Parameters: - dimension (int) – The latent factor dimension of the factormodel.
- begin_min (double) – The factors are initialized randomly, sampling each element uniformly from the interval (begin_min, begin_max).
- begin_max (double) – See begin_min.
- learning_rate (double) – The learning rate used in the stochastic gradient descent updates.
- negative_rate (int) – The number of negative samples generated after each update. Useful for implicit recommendation.
- number_of_iterations (int) – Number of times to iterate over the training data.
- cumulative_item_updates (boolean) – Cumulative item updates make the model faster but less accurate.