alpenglow package¶
Subpackages¶
- alpenglow.evaluation package
- alpenglow.experiments package
- Submodules
- alpenglow.experiments.ALSFactorExperiment module
- alpenglow.experiments.ALSOnlineFactorExperiment module
- alpenglow.experiments.AsymmetricFactorExperiment module
- alpenglow.experiments.BatchAndOnlineFactorExperiment module
- alpenglow.experiments.BatchFactorExperiment module
- alpenglow.experiments.ExternalModelExperiment module
- alpenglow.experiments.FactorExperiment module
- alpenglow.experiments.FmExperiment module
- alpenglow.experiments.NearestNeighborExperiment module
- alpenglow.experiments.OldFactorExperiment module
- alpenglow.experiments.PersonalPopularityExperiment module
- alpenglow.experiments.PopularityExperiment module
- alpenglow.experiments.PopularityTimeframeExperiment module
- alpenglow.experiments.PosSamplingFactorExperiment module
- alpenglow.experiments.SvdppExperiment module
- alpenglow.experiments.TransitionProbabilityExperiment module
- Module contents
- alpenglow.offline package
- Subpackages
- alpenglow.offline.evaluation package
- alpenglow.offline.models package
- Submodules
- alpenglow.offline.models.ALSFactorModel module
- alpenglow.offline.models.AsymmetricFactorModel module
- alpenglow.offline.models.FactorModel module
- alpenglow.offline.models.NearestNeighborModel module
- alpenglow.offline.models.PopularityModel module
- alpenglow.offline.models.SvdppModel module
- Module contents
- Submodules
- alpenglow.offline.OfflineModel module
- Module contents
- Subpackages
- alpenglow.utils package
Submodules¶
alpenglow.Getter module¶
- class alpenglow.Getter.Getter[source]¶
Bases:
objectResponsible for creating and managing cpp objects in the
alpenglow.cpppackage.- collect_ = {}¶
- items = {}¶
- class alpenglow.Getter.MetaGetter(a, b, c)[source]¶
Bases:
typeMetaclass of
alpenglow.Getter.Getter. Provides utilities for creating and managing cpp objects in thealpenglow.cpppackage. For more information, see Python API.
alpenglow.OnlineExperiment module¶
- class alpenglow.OnlineExperiment.OnlineExperiment(seed=254938879, top_k=100)[source]¶
Bases:
alpenglow.ParameterDefaults.ParameterDefaultsThis is the base class of every online experiment in Alpenglow. It builds the general experimental setup needed to run the online training and evaluation of a model. It also handles default parameters and the ability to override them when instantiating an experiment.
Subclasses should implement the
config()method; for more information, check the documentation of this method as well.Online evaluation in Alpenglow is done by processing the data row-by-row and evaluating the model on each new record before providing the model with the new information.
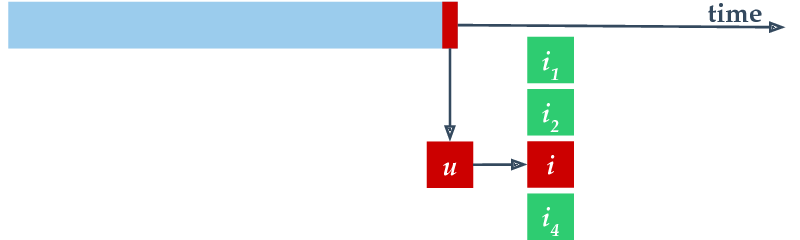
Evaluation is done by ranking the next item on the user’s toplist and saving the rank. If the item is not found in the top
top_kitems, the evaluation step returnsNaN.For a brief tutorial on using this class, see Five minute tutorial.
- Parameters
seed (int) – The seed to initialize RNG-s. Should not be 0.
top_k (int) – The length of the toplists.
network_mode (bool) – Instructs the experiment to treat
dataas a directed graph, withsourceandtargetcolumns instead ofuseranditem.
- get_predictions()[source]¶
If the
calculate_toplistsparameter is set when callingrun, this method can used to acquire the generated toplists.- Returns
DataFrame containing the columns record_id, time, user, item, rank and prediction.
record_id is the index of the record begin evaluated in the input DataFrame. Generally, there are
top_krows with the same record_id.time is the time of the evaluation
user is the user the toplist is generated for
item is the item of the toplist at the rank place
prediction is the prediction given by the model for the (user, item) pair at the time of evaluation.
- Return type
pandas.DataFrame
- run(data, experimentType=None, columns={}, verbose=True, out_file=None, exclude_known=False, initialize_all=False, calculate_toplists=False, experiment_termination_time=0, memory_log=True, shuffle_same_time=True, recode=True)[source]¶
- Parameters
data (pandas.DataFrame or str) – The input data, see Five minute tutorial. If this parameter is a string, it has to be in the format specified by
experimentType.experimentType (str) – The format of the input file if
datais a stringcolumns (dict) – Optionally the mapping of the input DataFrame’s columns’ names to the expected ones.
verbose (bool) – Whether to write information about the experiment while running
out_file (str) – If set, the results of the experiment are also written to the file located at
out_file.exclude_known (bool) – If set to True, a user’s previosly seen items are excluded from the toplist evaluation. The
evalcolumns of the input data should be set accordingly.calculate_toplists (bool or list) – Whether to actually compute the toplists or just the ranks (the latter is faster). It can be specified on a record-by-record basis, by giving a list of booleans as parameter. The calculated toplists can be acquired after the experiment’s end by using
get_predictions. Setting this to non-False implies shuffle_same_time=Falseexperiment_termination_time (int) – Stop the experiment at this timestamp.
memory_log (bool) – Whether to log the results to memory (to be used optionally with out_file)
shuffle_same_time (bool) – Whether to shuffle records with the same timestamp randomly.
recode (bool) – Whether to automatically recode the entity columns so that they are indexed from 1 to n. If
False, the recoding needs to be handled before passing the DataFrame to therunmethod.
- Returns
Results DataFrame if memory_log=True, empty DataFrame otherwise
- Return type
DataFrame
alpenglow.ParameterDefaults module¶
alpenglow.PythonModel module¶
- class alpenglow.PythonModel.SubModel(parent)[source]¶
Bases:
alpenglow.cpp.PythonModel
- class alpenglow.PythonModel.SubUpdater(parent)[source]¶
Bases:
alpenglow.cpp.Updater